Compose 运行原理与 GapBuffer
揭秘 @Composable
如果你已经看过 Compose,你可能在很多的示例代码中看到过 @Composable 注解。有一件很重要的事必须说明,Compose 没有使用注解处理器。Compose 在 Kotlin 编译插件在类型检查和代码生成阶段工作,因此不需要使用注解处理器。
这个注解更像是一个关键字。就像 Kotlin 里面的 suspend 关键字一样。
// function declaration
suspend fun MyFun() { … }
// lambda declaration
val myLambda = suspend { … }
// function type
fun MyFun(myParam: suspend () -> Unit) { … }
Kotlin 的 suspend 关键字会用在函数类型,你可以定义一个函数、lambda 或者是类型是 suspend 的。Compose 也一样,它可以改变函数的类型。
// function declaration
@Composable fun MyFun() { … }
// lambda declaration
val myLambda = @Composable { … }
// function type
fun MyFun(myParam: @Composable () -> Unit) { … }
有一点很重要这里必须要说明,当你为一个函数添加了 @Composable 注解时,你就改变了这个函数类型。也就是说,相同函数类型没有注解和有注解是不兼容的。同样的,suspend 函数也需要一个调用的上下文,意思就是只能在只能在另一个 suspend 函数里面调用 suspend 函数。
fun Example(a: () -> Unit, b: suspend () -> Unit) {
a() // allowed
b() // NOT allowed
}
suspend fun Example(a: () -> Unit, b: suspend () -> Unit) {
a() // allowed
b() // allowed
}
Composable 工作方式也是一样的。因为有一个调用上下文的对象贯穿这整个调用。
fun Example(a: () -> Unit, b: @Composable () -> Unit) {
a() // allowed
b() // NOT allowed
}
@Composable
fun Example(a: () -> Unit, b: @Composable () -> Unit) {
a() // allowed
b() // allowed
}
基于 GapBuffer 的运行过程
那么,这个我们传递的上下文是什么呢?还有为什么我们需要这么做?
我们把这个对象叫 “Composer”。Composer 的实现包含了一个跟 Gap Buffer 很类似的数据结构。这个数据结构经常用在文本编辑器里面。
Gap Buffer 表示的是一个包含了 index 和 cursor 的集合。在内存里面它就是一个扁平的数组。这个扁平的数组会比实际表示的数据要大一些,其中没有使用的空间就是 gap。

现在,一个正在执行的 Composable 层级会用这个数据结构插入数据。
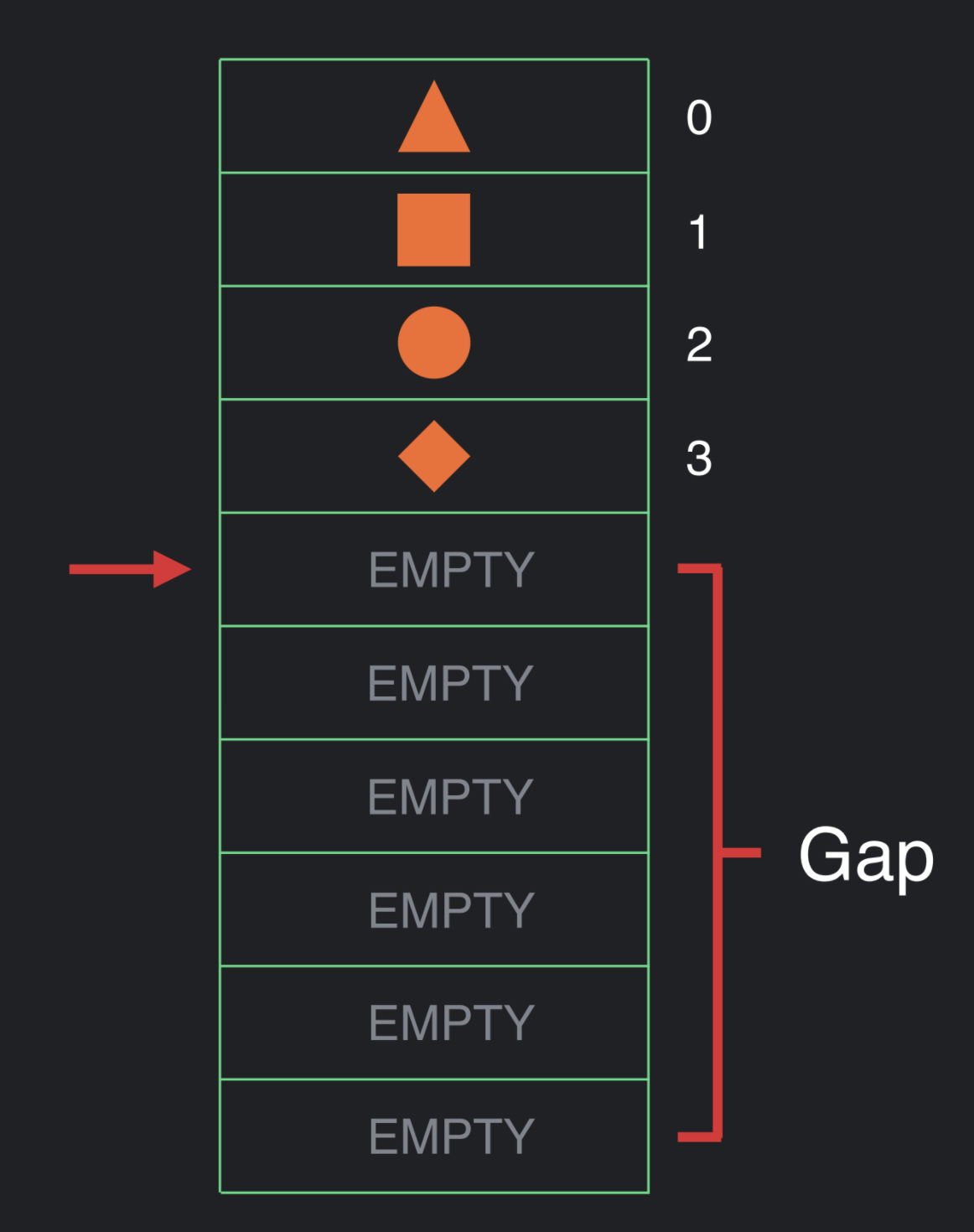
假设我们已经完成了这个层级结构的数据插入。有时候,我们需要 rcompose,因此我们需要重置 cursor 到数组的顶部并重新再次遍历整个数组。当我们在执行的时候我们可以根据数据看是否需要更新值。
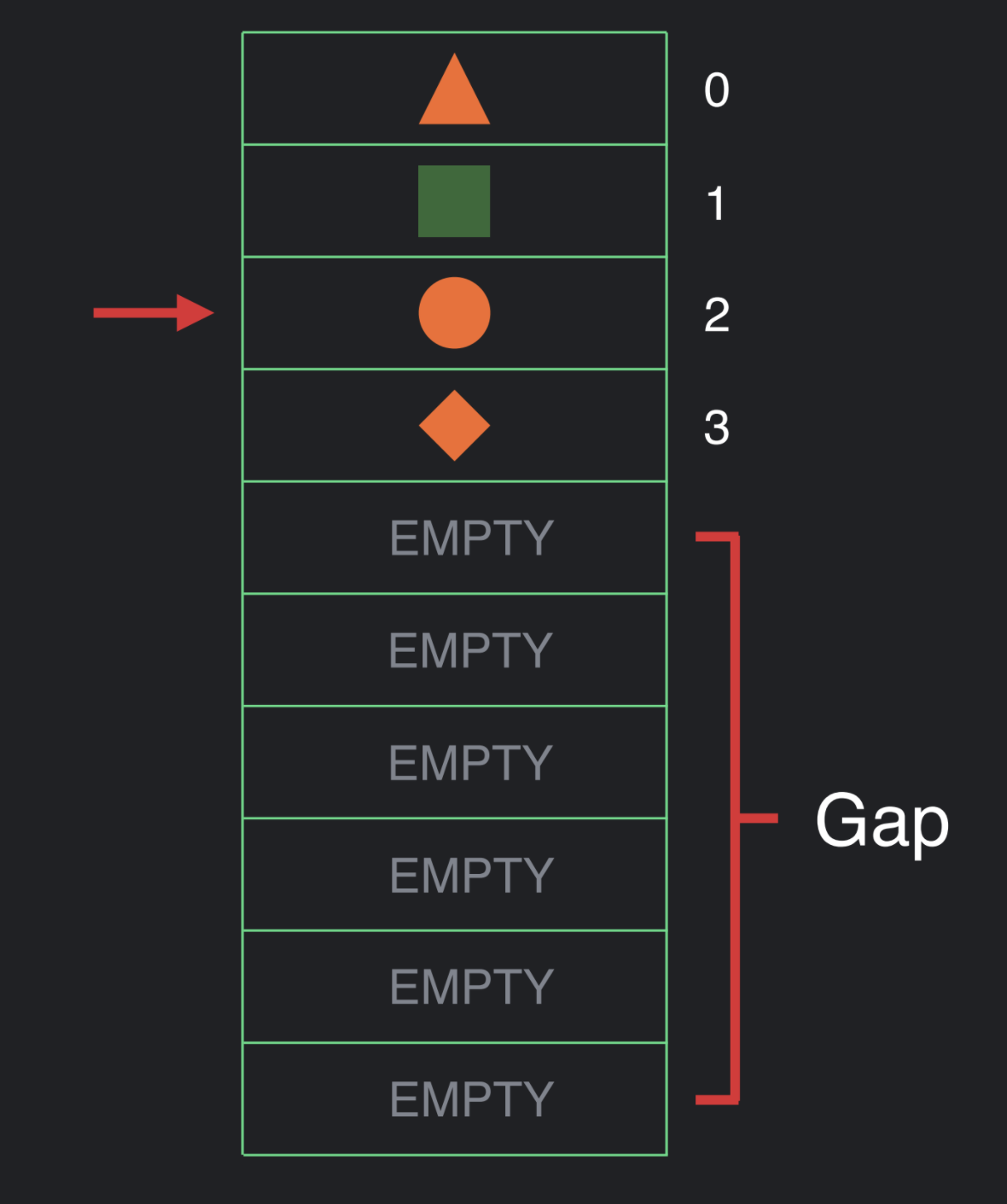
可能因为UI结构的改变我们想要插入数据,这个时候我们就把 gap 移动到了当前的位置。
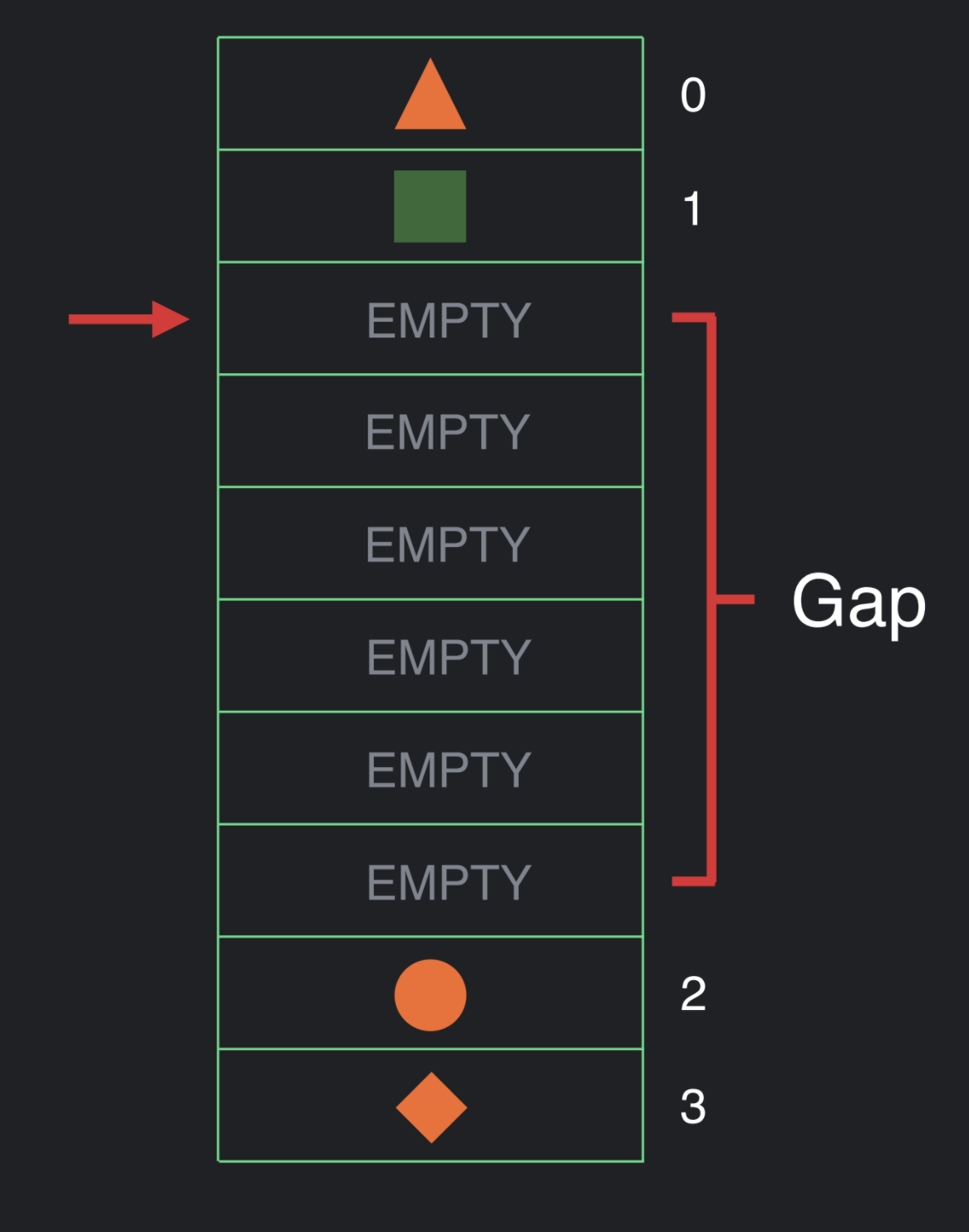
现在我们可以插入数据了。
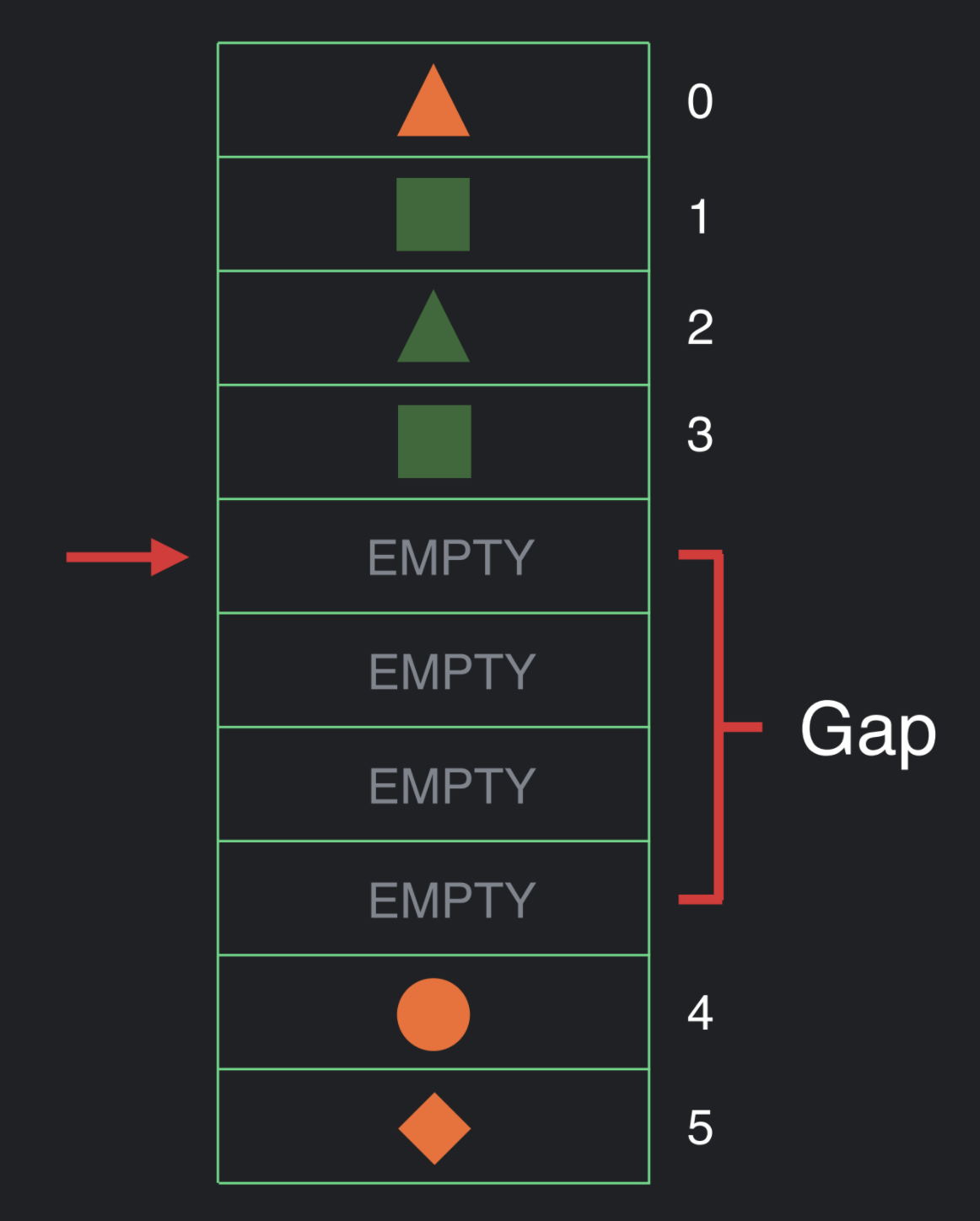
很重要的一点是我们需要理解这个数据结构的所有的操作—— get, move, insert, delete ——都是常量阶时间复杂度的操作,除了移动gap时间复杂度是 O(n)。我们选择这个数据结构的原因是因为我们认为,平均来说,UI 结构的变化不会太多。动态的UI通常是根据数据值的变化,而结构的变化不会经常发生。如果确实发生了结构行的变化,通常是一大块的变化,因此执行 O(n) 复杂度的 gap 移动也是合理的权衡。
让我们看一个 counter 的示例:
@Composable
fun Counter() {
var count by remember { mutableStateOf(0) }
Button(
text = "Count: $count",
onClick = { count += 1 }
)
}
我们写代码会这么写,编译器会为我们做什么呢?
当编译器看到 Composable 注解时便会插入额外的参数并在函数体内调用。
首先,编译器添加了一个 Composer.start 的调用并传入一个在编译期生成的整型关键字。
fun Counter($composer: Composer) {
$composer.start(123)
var count by remember { mutableStateOf(0) }
Button(
text = "Count: $count",
onClick = { count += 1 }
)
$composer.end()
}
编译器还把 Composer 的对象传递到了所有的函数体内部有 Composable 的地方。
fun Counter($composer: Composer) {
$composer.start(123)
var count by remember($composer) { mutableStateOf(0) }
Button(
$composer,
text = "Count: $count",
onClick = { count += 1 },
)
$composer.end()
}
当一个 Composer 执行,它做了下面这些事情:
Composer.start被执行了,并且保存了一个组对象remember插入的组对象- 状态实例
mutableStateOf返回的值被存储了下来 Button每个参数后面也持有了一个组对象
最后我们走到了 Composer.end。
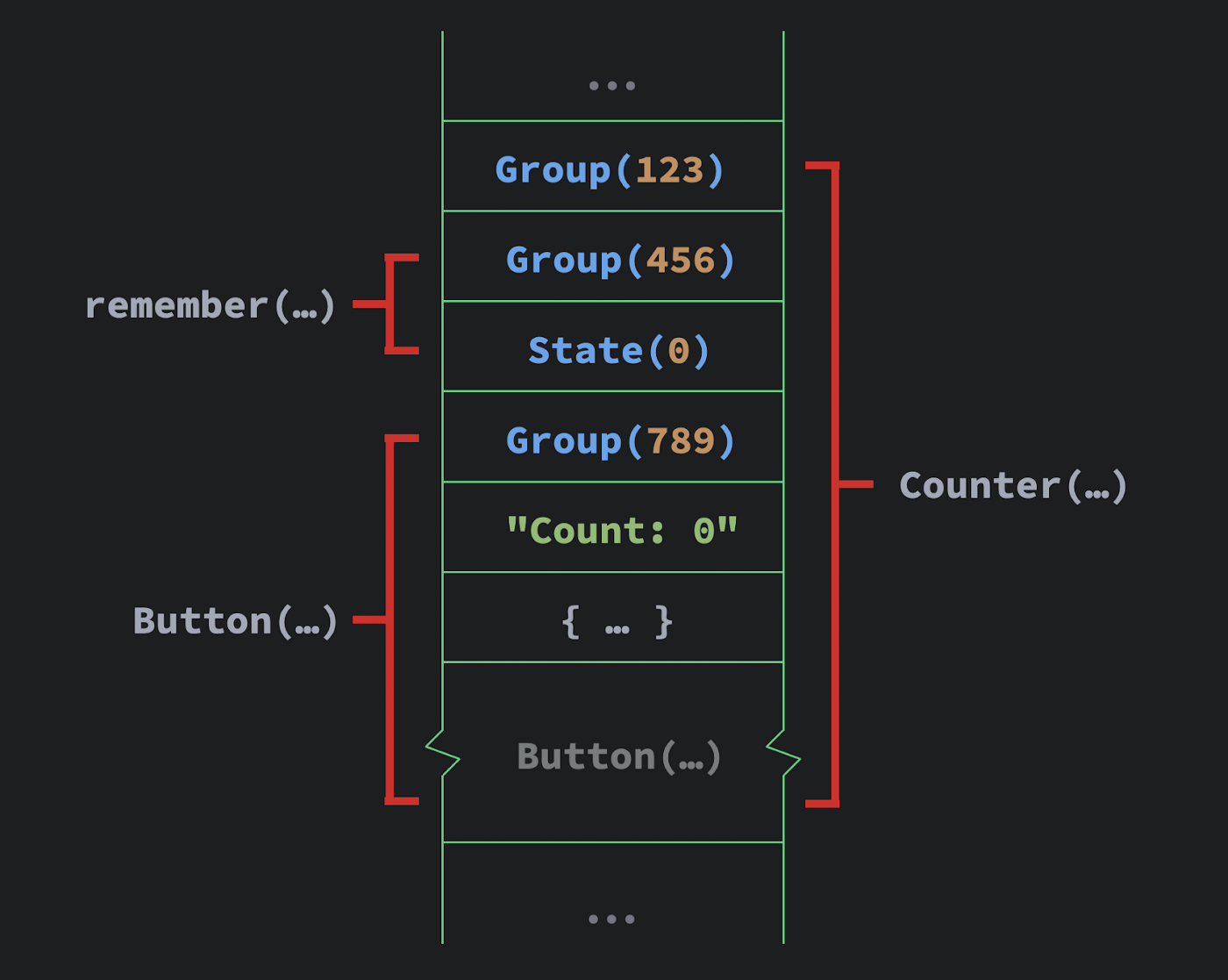
现在这个数据结构持有了这个 composition 的所有对象,按照整个树的执行顺序排序,实际上是整个树的深度优先遍历。
现在所有这些组对象占用了很多的空间,那这到底是为了什么呢?这些组对象存在的目的是为了管理 move 和 insert 这些可能发生在动态UI的操作。编译器知道会改变 UI 结构代码是什么样子,因此它可以根据条件来插入这些组。大部分情况下,编译器不需要这些组,因此它不会插入那么多的组到 slot table 里面。为了演示具体情况我们看下面这个条件逻辑。
@Composable
fun App() {
val result = getData()
if (result == null) {
Loading(...)
} else {
Header(result)
Body(result)
}
}
在这个 Composable 里面,getData 函数会返回一些结果,当 result == null 时会渲染 Loading ,在另一个场景下会渲染 Header 和 Body 。编译器会分别插入两个不同的整形关键字给 if 语句的条件分支。
fun App($composer: Composer) {
val result = getData()
if (result == null) {
$composer.start(123)
Loading(...)
$composer.end()
} else {
$composer.start(456)
Header(result)
Body(result)
$composer.end()
}
}
让我们假设一开始这个代码执行结果返回的是 null。那么就是插入一个组到 gap 数组里面,然后屏幕开始 loading。
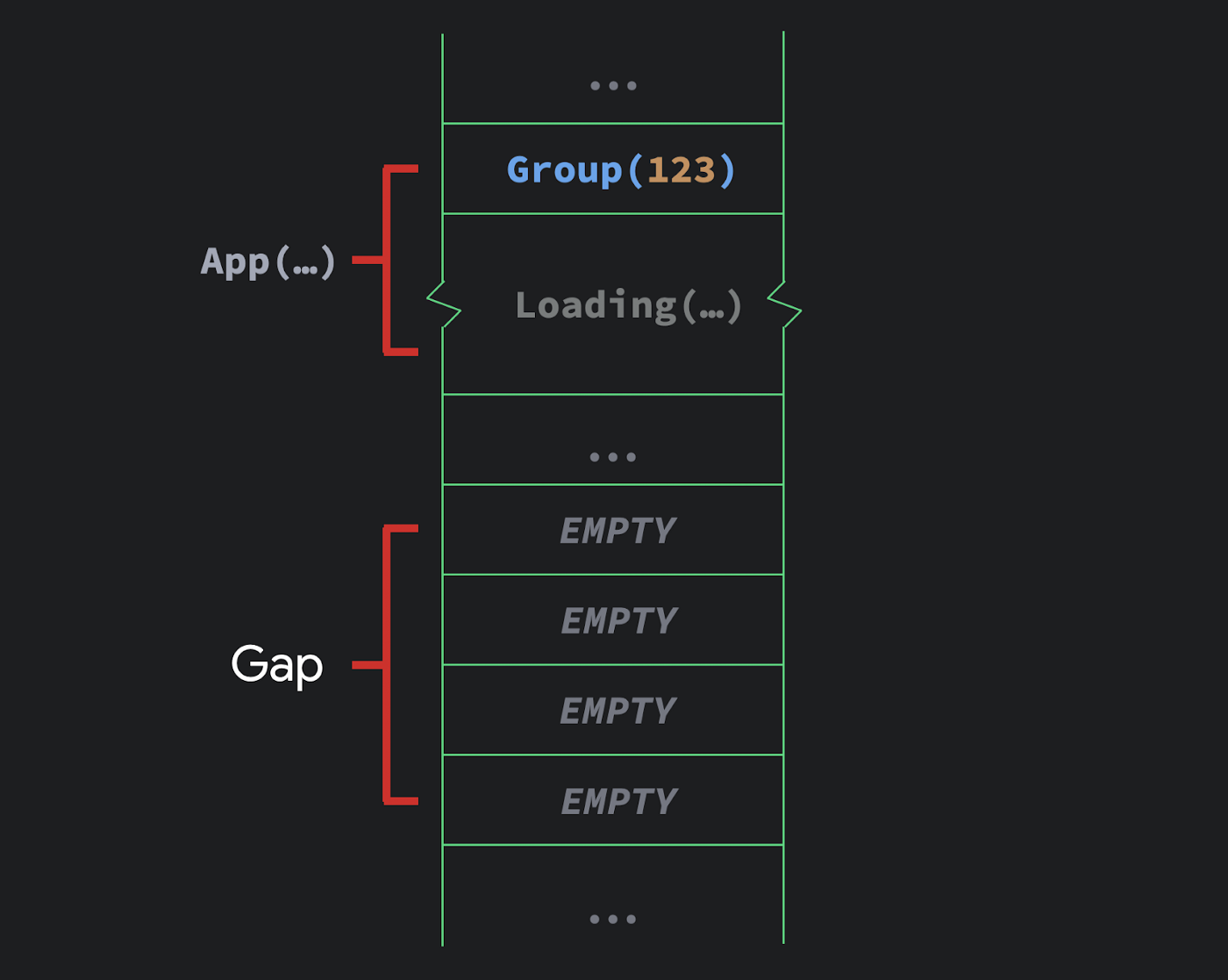 >
>接着我们假设返回的结果不再是 null,因此 if 语句的第二个分支被执行了。这也是它有意思的地方。
Composer.start 执行入了一个整形关键字为 456 的组。编译器发现这个组跟表里面的 123 不匹配,因此它知道 UI 的结构发生了变化。
然后编译器就把 gap 移动到当前的位置并扩大,实际上舍弃了旧的 UI。
这个时候,代码正常执行,还有新的 Header 和 Body 都被插入进来。
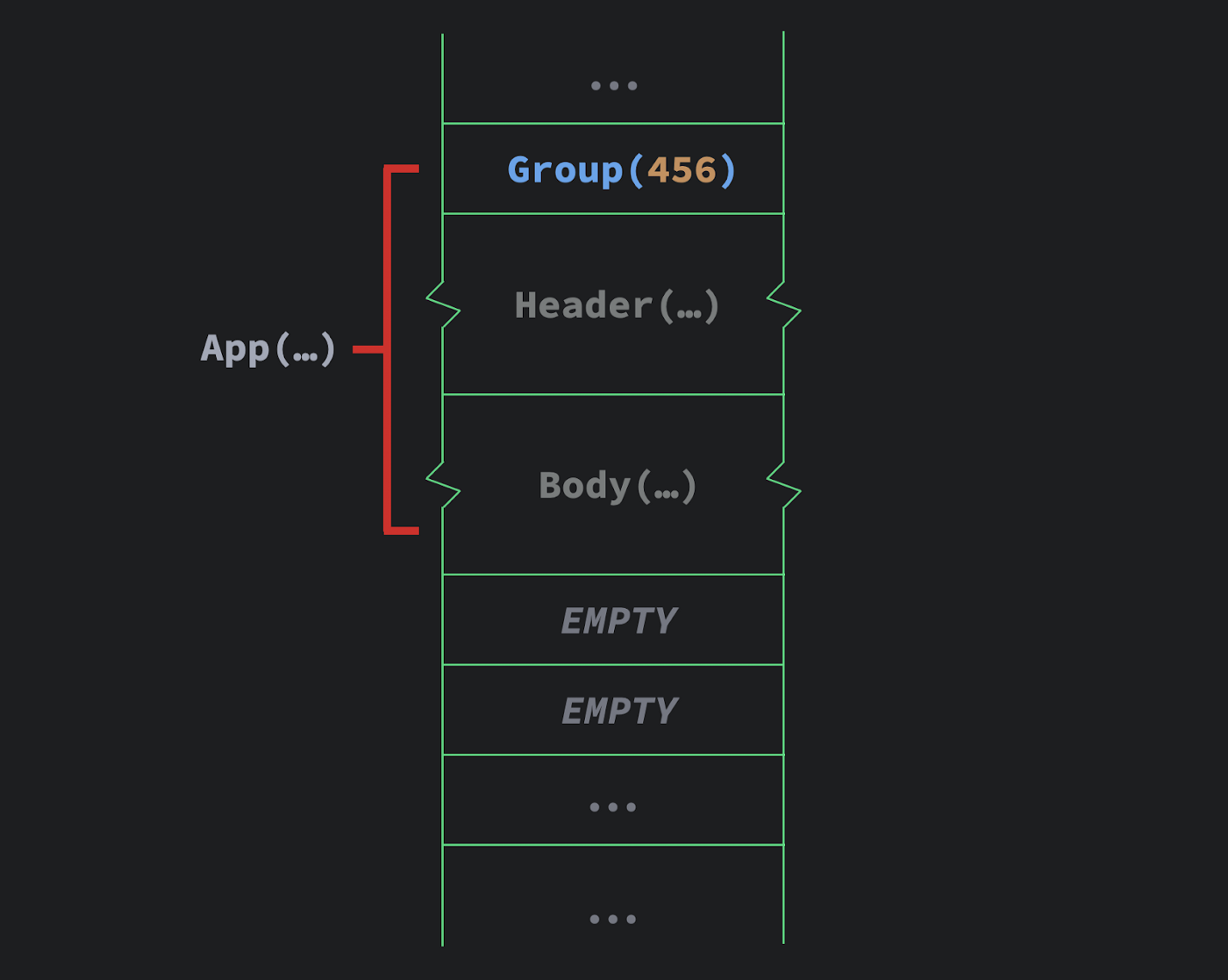
在这个例子里面,if 语句只是 slot table 里一个 slot entry。通过插入一个组让我们能够操控 UI 的控制流,让编译器能够去管理,当在执行 UI 的时候可以用这些类似缓存的数据结构。
这个概念我们称其为“基于位置的 memoization ”,这也是 Compose 始终在使用的概念。
基于位置的 memoization
通常,我们有一个通用的 memoization ,其含义是编译器会根据函数输入的参数缓存函数的结果。为了说明基于位置的 memoization,我们创建了一个 Composable 来执行一些计算。
@Composable
fun App(items: List<String>, query: String) {
val results = items.filter { it.matches(query) }
// ...
}
这个函数传入一个 items 列表和一个 query 字符串,然后执行了针对传入的 items 做了一个 filter 过滤计算。我们可以把这个计算包装到一个记录的调用里面(记录指的是知道怎么像表发起请求)。在返回之前,这个过滤器计算完并且把结果记录下来。
当这个函数再次被执行的时候,拿新传递进来的值同历史记录做对比,如果没变化,过滤操作会被跳过,之前的结果直接返回。这就是 memoization。
有趣的是,这个操作开销很小,编译器只需要存储之前的调用。这个计算可能会发生在整个 UI 的过程中,因为你是根据位置存储的,只有在那个位置才会存储。
下面是 remember 函数的签名,它是一个可变参数和计算函数的作为参数的函数。
@Composable
fun <T> remember(vararg inputs: Any?, calculation: () -> T): T
这里有一个比较有意思的退化场景,在没有参数的时候,我们能做的一件事就是故意错误使用这个 API。我们可以故意传一个脏数据进行计算,比如 Math.random()。
@Composable fun App() {
val x = remember { Math.random() }
// ...
}
如果你正在做的是一个全局的 memoization 的话那就没有意义。但是基于位置的 memoization,它将会是一个新的语义。每次我们用 Composable 的层级,Math.random 都会返回新值。但是,每次 Composable 被重新组合的时候,Math.random 都会返回相同的值。这样就可以持久化,持久化就可以进行状态管理了。
存储参数
为了演示 Composable 函数的参数是怎么被保存的,我们用 Google 这个 Composable函数,它有一个 Int 类型的 number 入参,里面调用了一个叫 Address 的 Composable,然后渲染Address。
@Composable
fun Google(number: Int) {
Address(
number=number,
street="Amphitheatre Pkwy",
city="Mountain View",
state="CA"
zip="94043"
)
}
@Composable
fun Address(
number: Int,
street: String,
city: String,
state: String,
zip: String
) {
Text("$number $street")
Text(city)
Text(", ")
Text(state)
Text(" ")
Text(zip)
}
compose 将 Composable 函数的参数保存在表里面。如果是这样的话,我们看下上面的例子会有一些冗余,“Mountain View” 和 “CA”,这两个添加到地址里面会随着文本的调用再次存储,因此这些字符串会被存储两次。
我们可以在编译阶段通过添加 static 的参数来避免这种冗余。
fun Google(
$composer: Composer,
$static: Int,
number: Int
) {
Address(
$composer,
0b11110 or ($static and 0b1),
number=number,
street="Amphitheatre Pkwy",
city="Mountain View",
state="CA"
zip="94043"
)
}
这个例子中 static 是一个整数字段表示运行时是否知道参数有没有发生改变。如果参数没变,那么就没必要去存数据。因此在这个 Google 的例子里面,编译器传入了一个参数用以表示是否会发生改变。
那么在 Address 里,编译器同样可以这么做,把它传给字符串。
fun Address(
$composer: Composer,
$static: Int,
number: Int, street: String,
city: String, state: String, zip: String
) {
Text($composer, ($static and 0b11) and (($static and 0b10) shr 1), "$number $street")
Text($composer, ($static and 0b100) shr 2, city)
Text($composer, 0b1, ", ")
Text($composer, ($static and 0b1000) shr 3, state)
Text($composer, 0b1, " ")
Text($composer, ($static and 0b10000) shr 4, zip)
}
这里的逻辑运算看起来比较晦涩也让人看起来比较困惑,但是我们没必要去理解它,这是编译器擅长的事情,我们不擅长处理。
在 Google 的示例里面,我们看到了冗余的信息,但也有一些常量。其实我们也没必要去存储它们。因此整个层级结构是由参数的数量决定的并且这也是唯一需要编译器去存储的。
正因如此,我们再进一步,生成了代码才理解那个数字是唯一会改变的东西。这段代码将会这样运行,如果这个数字没变的话,整个函数都会被跳过,然后我们可以引导 Composer 当前的 index 到下一个位置,就好像函数已经被执行了一样。
fun Google(
$composer: Composer,
number: Int
) {
if (number == $composer.next()) {
Address(
$composer,
number=number,
street="Amphitheatre Pkwy",
city="Mountain View",
state="CA"
zip="94043"
)
} else {
$composer.skip()
}
}
Composer 知道需要快进到哪一步去恢复执行。
重组
为了理解重组是怎么工作的,让我们再回头看下 counter 的例子。
fun Counter($composer: Composer) {
$composer.start(123)
var count = remember($composer) { mutableStateOf(0) }
Button(
$composer,
text="Count: ${count.value}",
onPress={ count.value += 1 },
)
$composer.end()
}
编译器给这个 counter 例子自动生成的代码有 composer.start 和 composer.end。不管 counter 什么时候执行,它通过读取 APP 模型实例的属性都能知道 count 的值。在运行时,不管什么时候调用 composer.end,我们都能选择是否返回值。
$composer.end()?.updateScope { nextComposer ->
Counter(nextComposer)
}
然后我们可以用该值调用 updateScope 方法,方法传一个 lambda 来告诉运行时在必要时怎么去重启这个 Composable。这个和 LiveData 接收一个 lambda 是一样。这里我们用可空(?)的原因是,返回值是可空的,为什么是可空的呢?因为如果我们在 Counter 运行的时候不读取任何模型对象,我们就没法告诉运行时怎么去更新,因为它永远不会更新。
结语
你需要知道的是大部分这些细节只是实现细节。标准 Kotlin 函数库里面 Composable 函数会有不同的行为和能力,有时候理解它们怎么实现会对我们有所帮助,但是行为和能力不会变,实现是有可能变的。
同样的,Compose 的编译器在特定情形下可以生成更高效的代码。后续,我们也希望能进一步优化。